Over the past few months I’ve converted just about every active project of mine from Subversion to Git. This now includes the Evri development projects, as well as my open source projects, and even home linux server code (i.e. the ruby script that runs this blog.)
Background
I was originally drawn to git based on its merits in supporting free forking of open source projects. Publishing several of my personal open source projects to github has cemented my appreciation. That said, as has been discussed broadly, the learning curve of git is quite steep. With this kind of power must come some complexity. Its relatively simple to push your sole project contributions to a github repo, but the first time I offered commits and a pull request off a fork of activerecord-jdbc-adapter I was a bit embarrassed to find that I really didn’t yet know what I was doing. That was a good lesson for me, perhaps learned the only practical way, and since then I’ve put a little extra git education time into just about every project. Milestones crossed:
- I’m no longer terrified by the unknown that was “git rebase”
- I’m only mildly leery of “git svn.”
Yes I will make my history look the way it should: nice independent linear patches, forward-only merges when possible, etc. And I think this is slowly starting to pay dividends in my development process. I’ve re-enabled some development tactics that I had previously decided, over the years of using SVN, CVS, and those before it, just weren’t worth the trouble. And I’ve learned some new tactics.
My mode of operation with Subversion had been to avoid branches and merging at all costs:
- Don’t check that in until I tag the next release!
- Lets split this code base up so we can work better in parallel!
While there remains merit in the last approach (appropriate modular decomposition), it shouldn’t be driven by limitations of a tool, and besides I never figured out exactly where to put those “trunk” directories.
Making the tools work
What parts of my development tool set need to change with git?
Maven might have been an issue (isn’t it always), but my recent conversion to java/ruby gems packaging has the convenient side effect of liberating me from the maven release plugin (though I’m told there is workable maven/git integration). I use rake for that now, and a simple “rake tag” task covers my git interaction.
I’m still inclined to use Eclipse, while its not ideal, as a java code editor, primarily for the refactoring support that java seems to need, as a junit test launcher, and occasional debugger. The egit plugin for eclipse works well for basic operations, but the command line is still my main interface to git.
But with merging in play, I really want my commits to be recognizable as clean atomic patch sets. An important aspect of this is not cluttering up those patches with arbitrary white noise in the form of randomly changing whitespace. With emacs, there is whitespace-mode and surrounding commands. Problem solved for all files accept java, but Eclipse is just not that sophisticated as a text editor.
cleanws script
So I worked up a new tool. Its a simple text file whitespace filter, but I’ve also added some nice git integration and color coding to make it reasonably convenient. Ruby BTW is quite nice for this kind of task. Before doing a “git add”, I run “cleanws -g” to ensure good canonical whitespace in new/updated files. See the following example:
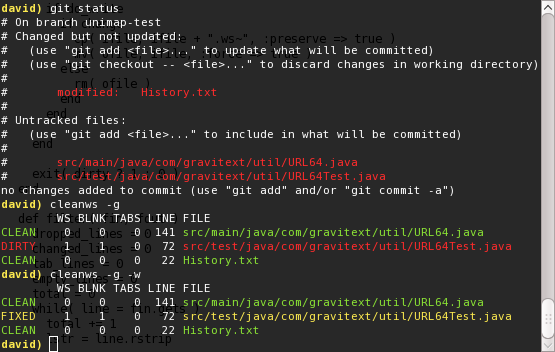
The second call fixes the file and (-w)rites it to disk. Any detected evil tab characters are left in place to be manually resolved.
Here is the full script. Perhaps it will find its way into a gem and github it there is interest or if I continue to expand on it. Enjoy, and please keep it clean out there.